
I was trying to answer a simple question: which LLM is actually the best for coding right now?
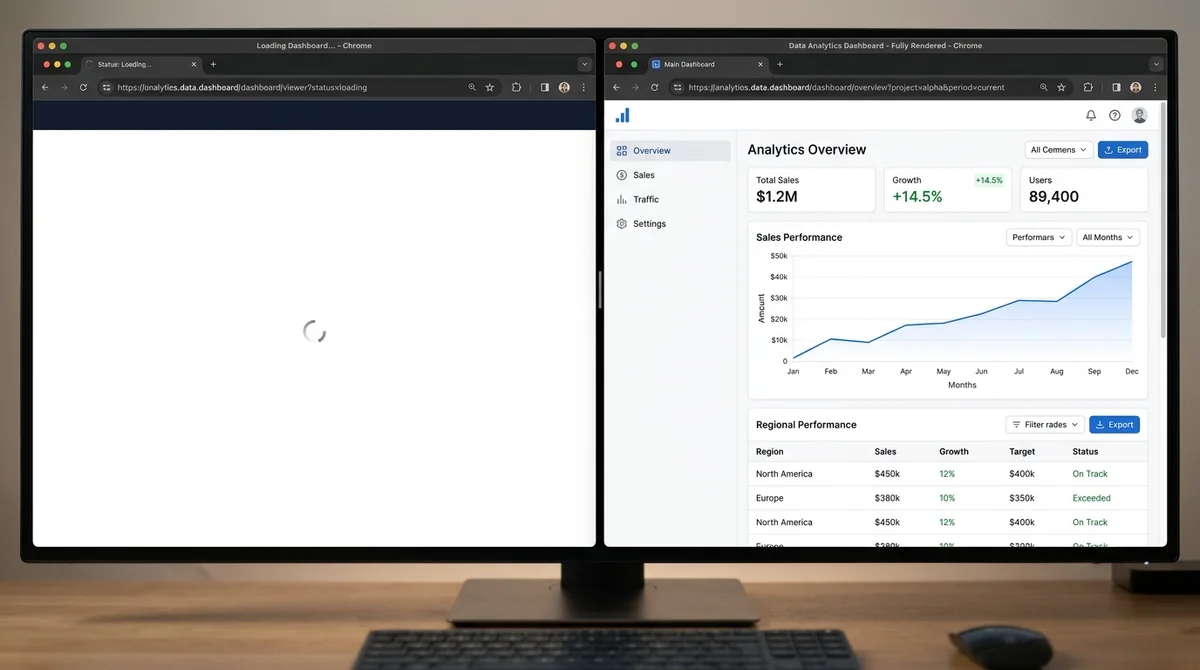
So I did what anyone would do. I asked Claude to pull the latest benchmark data from LiveBench, LiveCodeBench, and Chatbot Arena. The results came back empty. Not because the data doesn't exist, but because these sites are single-page applications that render everything with JavaScript on the client side. AI crawlers — including the one powering this very conversation — can't execute JavaScript. They fetch the raw HTML, find an empty div, and move on.
The irony is hard to overstate. The sites that rank AI models are invisible to AI.
The SPA problem in 30 seconds
A single-page application (SPA) loads one empty HTML shell, then JavaScript builds the entire page in the browser. This works fine for humans. Google's crawler handles it too, since Googlebot runs a full headless Chrome instance.
But GPTBot, ClaudeBot, PerplexityBot, and every other AI crawler don't execute JavaScript. An analysis of over 500 million GPTBot requests found zero evidence of JavaScript execution. When these crawlers visit LiveBench or the Arena leaderboard, they see nothing.
Server-side rendering (SSR) solves this by building the full HTML on the server before sending it to the browser. The content exists in the initial response — every crawler, every AI model, every search engine can read it immediately.
What I built
I built a benchmark aggregator that does three things differently.
First, it uses headless Chromium via Playwright to crawl the JS-rendered leaderboard sites on a schedule. The crawler navigates to each site, waits for the data tables to render, extracts the structured data, and normalizes it into a consistent format.
Second, it serves everything as static HTML with server-side rendering through Next.js. Every model name, every score, every price point is in the raw HTML response. When an AI crawler visits my benchmarks page, it gets the complete dataset — not an empty shell.
Third, it pulls live discussion from Reddit communities like r/LocalLLaMA, r/ClaudeAI, r/OpenAI, and r/singularity. Quantitative benchmark scores alongside qualitative community sentiment, all on one page.
The data refreshes automatically twice daily via GitHub Actions. Failed crawls never overwrite good data. A sanity filter drops garbage entries before they reach the page.
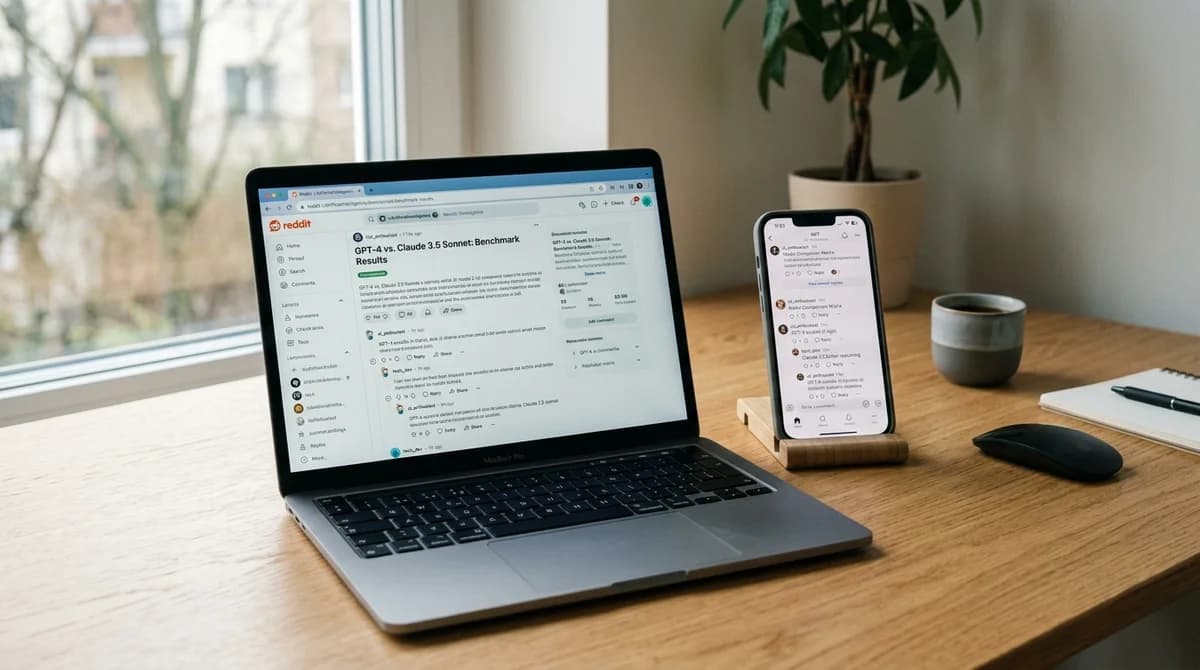
What the data actually shows (April 2026)
The rankings depend entirely on what you measure.
On Code Arena (human preference votes for coding tasks), Claude Opus 4.6 leads with an Elo of 1546. The top 5 is dominated by Anthropic models.
On LiveBench (contamination-free objective scoring), GPT-5.4 Thinking leads at 80.3%, with Gemini 3.1 Pro close behind at 79.9%. Claude Opus 4.6 drops to 76.3%.
On LiveCodeBench (competitive programming problems), the picture shifts again — different models trading places depending on difficulty level.
No single model wins everywhere. The "best" one depends on your workload, your budget, and the type of task you actually care about. That's exactly why seeing all the benchmarks side by side matters.

Why this matters for businesses
If you're evaluating AI models for your company, one benchmark and one blog post comparison won't cut it. The landscape changes weekly. Models that led three months ago are mid-pack today. Pricing shifts constantly.
A live, aggregated view across multiple benchmarks gives you something no single source can — and because my page is server-rendered, you can ask your AI assistant to read it directly and summarize the current state for you.
Check the live data
My benchmarks page is free, updated twice daily, and readable by both humans and AI: seelig.ai/benchmarks
If you need help picking the right model for your specific use case, workflow, and budget — that's what I do. Get in touch.